
CS log
Network Layer : Internet Protocol 본문
지난 시간 배운 내용
- host에선 3계층 Network layer의 기능인 routing과 forwarding을 모두 갖는다.
F. host는 default router로의 forwarding만 이루어지며, static하게 사람이 setting 하는 forwarding table만 가짐.
routing table은 routing protocol이 알아서 관리하는 table이며 host에는 routing protocol이 없음 - Network 계층은 인터넷이 연결된 라우터와 host에 모두 다 있다.
T. - Network service model
- individual datagram 차원에선 no loss, no delay 등
- a flow of datagrams 차원에선 in-order delivery, low delay jitter
⇒ IP 프로토콜은 위의 모든 것을 지원하지 않고 TCP가 함
- Internet에 사용되는 layer 3 protocol(IP)은 no loss와 in-order delivery를 support한다
F. TCP가 하는 일, IP계층은 아무것도 하지 않는다. - Packet Switching은 Circuit Switching과 다르게 다양한 2계층을 interconnect하는데 유리하다.
T. Packet Switching은 아무런 guarantee가 없기 때문에 fiber optic이든 security가 안 좋은 wifi든 모든 아래 계층(2계층)을 지원한다. - internet - Virtual Circuit Packet Switching의 대표적인 예시는 ATM이다.
T. ATM은 SPEC에서 2계층까지 정의하고 있다. queue까지 예약해서 throughput을 예약해 resource reservation이 가능한 VC까지 있다. 적절한 network provisioning이면 realtime streaming service도 가능 - Packet Switching은 connectionless protocol이다.
T. IP Protocol도 connectionless protocol. 패킷 간 어떤 관계를 갖는지 기억하고 있지 않기 때문에 둘 다 connectionless protocol이다. 각각이 별도의 다른 route로 갈 수 있음. - 라우터에는 end host에서 출발한 application msg가 포함된 패킷 메시지만 지나간다.
F. 라우터에는 라우터들끼리 주고받는 msg들도 지나 다닌다.
라우터는 traditional router를 말하고, new paradigm router는 packet switch라고 부름. 라우터에는 control plane과 data plane이 함께 있음(forwarding 하는 보드와 routing protocol 보드가 함께 있음)
라우터 안에 들어오는 패킷은 end user의 msg를 싣고 오는 패킷도 있고(forwarding plan: 어떤 포트로 들어와 switching 보드를 거쳐 다시 어떤 포트로 나가는), 어느 라우터가 만들어낸 라우팅 프로토콜의 control msg가 들어와 다시 output port로 나갈 수도 있음. - New Paradigm인 SDN은/ routing protocol이 동작하는 control plane은/ routing protocol이 동작하는 machine과 실제 가입자의 data가 forwarding하여 지나가는 router가 분리되어 있다.
T. 가입자의 패킷이 지나가는 router들은 모여 있어야 함
control plane은 SW로 동작하기 때문에 다소 느림, data plane(switching 보드)는 HW로 동작하기 때문에 빠름
1. Switching fabrics (hardware)
switching: input buffer에서 output buffer에서 패킷 하나를 보내는 것 = forwarding
여러 port가 엮여 있기 때문에 fabric이라고 표현
- switching rate: 얼마나 빨리 switching 하느냐. (워낙 빠름)
input buffer에도 store를 위해 delay가 발생하지만, switching 속도가 워낙 빨라 overflow가 발생하지 않음
가입자의 data가 들어오는 line의 input buffer로 들어오는 속도(capacity)를 input link의 R이라고 하면, switching rate은 R의 몇 배임.
항상 line capacity의 몇 배. = line rate(R)의 몇 배냐? → no big deal - interconnection network (crossbar network)
switching 보드의 design. - 1) memory : 초기엔 가운데 memory를 두어 read, write하는 방식. 속도가 오래 걸림
- 2) bus : hardware적으로 bus를 마련. 속도는 빨라졌지만 동시 통신을 하지 못 함
- 3) interconnection network : 최근엔 interconnection network를 사용.
(여러 개의 node들을 연결하면 network. 여러 port가 여러 bus로 엮여 있기 때문에 network라고 함)
interconnection network로 여러 개의 패킷을 여러 port로 switching하는 것이 가능해짐. 단, 다른 input port에서 다른 output port로 가는 것만 가능함.
forwarding table(FIB)을 보고, input port에서 어떤 output port로 갈 지 결정
만약, 같은 output port로 가야 하는 패킷들이 동시에 들어온다면, 그 중 하나만 output port로 갈 수 있고, 나머지는 wait in input buffer. but switching rate이 높아 눈에 띄지 않을 정도로 지나가게 됨.
→ 여러 개의 패킷들을 switching 할 수 있지만, 서로 다른 output port로 가는 경우만 가능하다. - head of the line blocking
두 개의 서로 다른 input port로 들어온 패킷이 같은 output port로 나가고자 할 때, 둘 중 하나만 나갈 수 있고, 하나가 input port에서 기다리는 현상
2. Input port functions (switching fabric 가기 전!!)

- Physical layer : link가 달려 R의 rate으로 signal이 들어옴. signal이나 light가 들어와 bit로 변환.
- Link layer : framing. 줄줄이 들어오는 bit들에서 하나의 frame을 찾아 body(Datagram)만 NW에 올려줌.
- Network layer
- store & forward. Datagram이 들어옴. switching rate에 따라 나감.
- input buffer의 bit 들어오는 속도는 link rate인 R, 나가는 속도는 switching rate B.
- R<B(R*N). N은 대략 포트 개수. 항상 B가 더 커 ingress buffer에는 overflow x
- decentralized switching
- 중앙에 있는 control 보드로 가지 않고, local한 가입자 보드 안에 FIB를 보고 결정. 각각의 hw board에 가져다 놓음 . 들어오는 bit 바로 판단하게!
- given datagram, using header field(des.IP addr) values, lookup output port using forwarding table in input port memory
- switching은 어떤 input buffer에서 어떤 output buffer로 가야함.
- 어떤 output buffer로 가는지 이 안에서 해결이 가능! (FIB lookup)
- FIB lookup: 들어온 datagram의 헤더를 보고 FIB에서 dest. IP addr에 맞는 output port를 찾아 switching 해줌 ⇒ match plus action
- 그 때 필요한 FIB가 가입자 보드가 아닌 control 보드에 있다면/ 보드 사이의 통신 오버헤드가 발생할 수 있음. 중앙에서 계산한 RIB값을 FIB에 심어놓기에 control 보드까지 가지 않고(centralized), 가입자 보드 안의 FIB를 보고 결정할 수 있음.
- 스위칭 보드의 switching rate이 충분히 빠르지 않으면 뭐... delay가 생길 수 있음
- 중앙에 있는 control 보드로 가지 않고, local한 가입자 보드 안에 FIB를 보고 결정. 각각의 hw board에 가져다 놓음 . 들어오는 bit 바로 판단하게!
3. Head-of-the-Line (HOL) blocking
: input queue에서 **앞에 있는 놈 때문에 blocking이 일어나는 현상
t0에 switching 되어야 하는 data가 dest. output port가 같아 하나는 못 갔음.
t1에 switching 되려고 scheduling 되어있던 다음 data가 switching 되지 못 하고 앞에 있는 놈 때문에 one-packet-time 늦게 switching. 결과적으로 t2에 switching
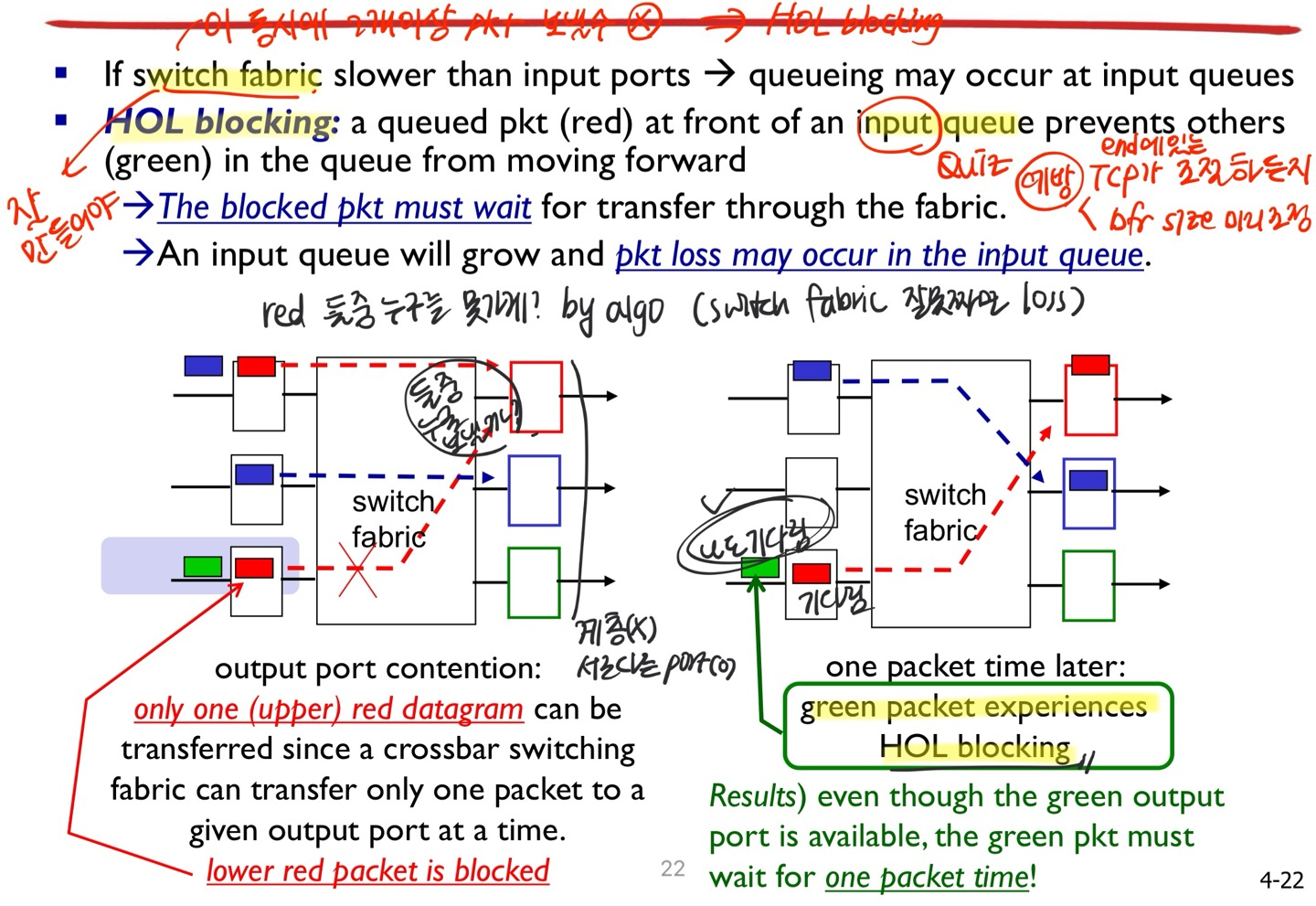
crossbar interconnection network의 단점 : 둘 이상의 input port에 들어온 패킷이 동일한 output port로 갈 때는 하나의 packet만 switching할 수 있다 → 나머지는 기다려야 하며 그 다음 packet time에 switching되기로 scheduling되어 있던 패킷들은 제 시간에 switching 되지 않고 한 타임 밀리게 되어 있음.
예방법 : end에 있는 TCP가 조절하든지, bfr size를 조정하든지
4. output port functions
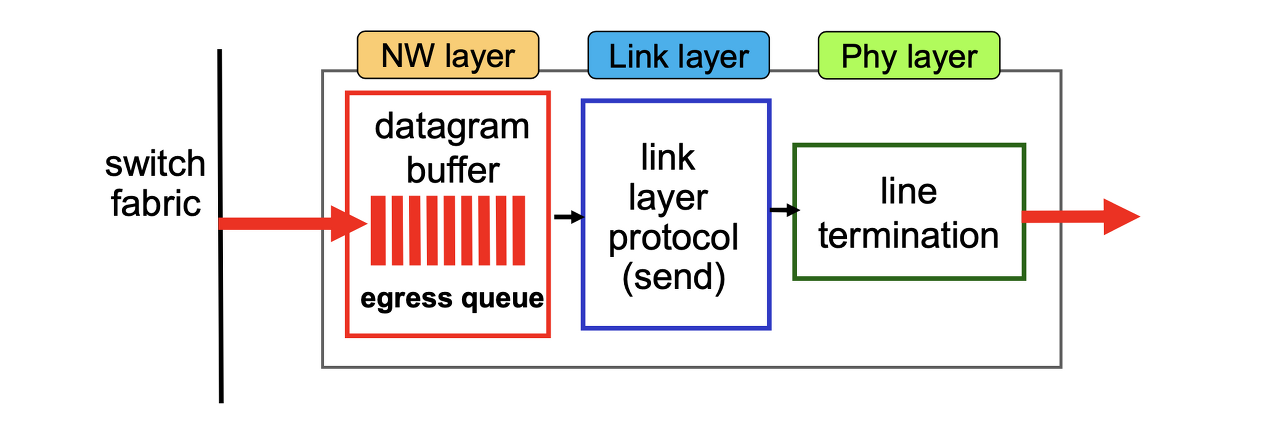
Data가 나가는 속도를 B라고 하면, B는 link rate인 R 값.
data가 들어오는 속도 a값은 switching rate? X. 해당 output port의 packet arrival rate.
- a > B 이면 loss, overflow. ⇒ ingress buffer에선 예측 불가능. 라우터를 지나는 가입자들의 data가 어느 시간대에 어느 서버로 몰리는지 예측할 수 없어 output port buffer에서 queueing delay와 loss가 생길 수 있다.
- output queue에서 대기하는 패킷들은 어떤 순서로 나갈까?
- FCFS: First Come, First Service (Internet)
network neutrality 망 중립성 원칙. 모든 인터넷을 돌아다니는 트래픽은 공정해야 한다.
어떤 가입자든 차별 없이 인터넷 속도를 공평하게 해야 한다.
but, 망 중립성에 의해 컨텐츠 사업자들이 망 이용에 대해 투자를 안 할 수 있음. - WFQ(Weighted fair queueing): premium service first (Other network)
큐를 여러 개 두거나 output buffer에서 priority 처리.
network neutrality가 깨지게 됨.
How much buffering at routers?
overflow가 일어나지 않으려면 output buffer의 size는 어때야 할까?
- average buffering (버퍼 사이즈에 대한 버퍼링 B의 양) = RTT * C (Link Capacity)
- rtt : 네트워크 요청을 시작한 후 응답을 받는 데 걸리는 시간
C: 버퍼에서 나가는 link의 용량에 따라 버퍼 사이즈를 조절.
RTT= number of hops (routers)는 network size에 비례.
RTT가 커진다는 것은 end to end를 지나가는데 router가 그만큼 더 많이 필요하다는 것
network size가 크다는 것은 end로 가는 패킷이 어떤 한 라우터에 포함된 버퍼에 평균적으로 머무르는 시간이 길다는 것. 따라서 버퍼 사이즈에 RTT값을 반영 해야 함.
rtt가 커지면 bft도 커져야함 왜냐하면 타 pkt과 더 같이 있어야 하기 때문 -> internet size도 커진다.
- TCP flows (N)값을 반영해야 한다. buffering = RTT * C / √N
* output buffer와 TCP의 관계.
TCP Connection이 많아진다는 것은 output buffer에 들어오는 패킷들을 관리하는 end가 많다는 것. buffer가 overflow하지 않도록 flow control 하는 TCP가 많을수록 버퍼 용량이 관리가 되니 √N으로 나눈 것.
⇒ RTT (네트워크 사이즈) * C (output buffer에 물린 link capacity) / √N (TCP Conn. 개수)
4.3 Internet Protocol (IP)
- datagram format & fragmentation
- IPv4 addressing
- network address translation (NAT)
- IPv6
Internet network layer(2020 ver.)

IP protocol : Network Layer의 Data plane은 NW router에도, host에도 있음
routing protocols : Control Plane에서 routing protocol은 only at NW routers, host에는 x.
- path selection (algorithm)
Ex. 다익스트라, 벨만포드 알고리즘 - RIP, OSPF, BGP (Routing protocol)
path selection algorithm 작동을 위한 라우터들 간의 프로토콜
ICMP protocol
ICMP protocol은 IP Protocol이 유일하게 하는 기능. end에게 report.
Internet Control Message Protocol. 라우터, host 모두 발생시킬 수 있음.
Ex. host가 생성하는 가장 대표적인 ICMP protocl은 Ping.
$ ping [first gateway router IP address] → ICMP msg 보내고 받음
(2023 ver.)
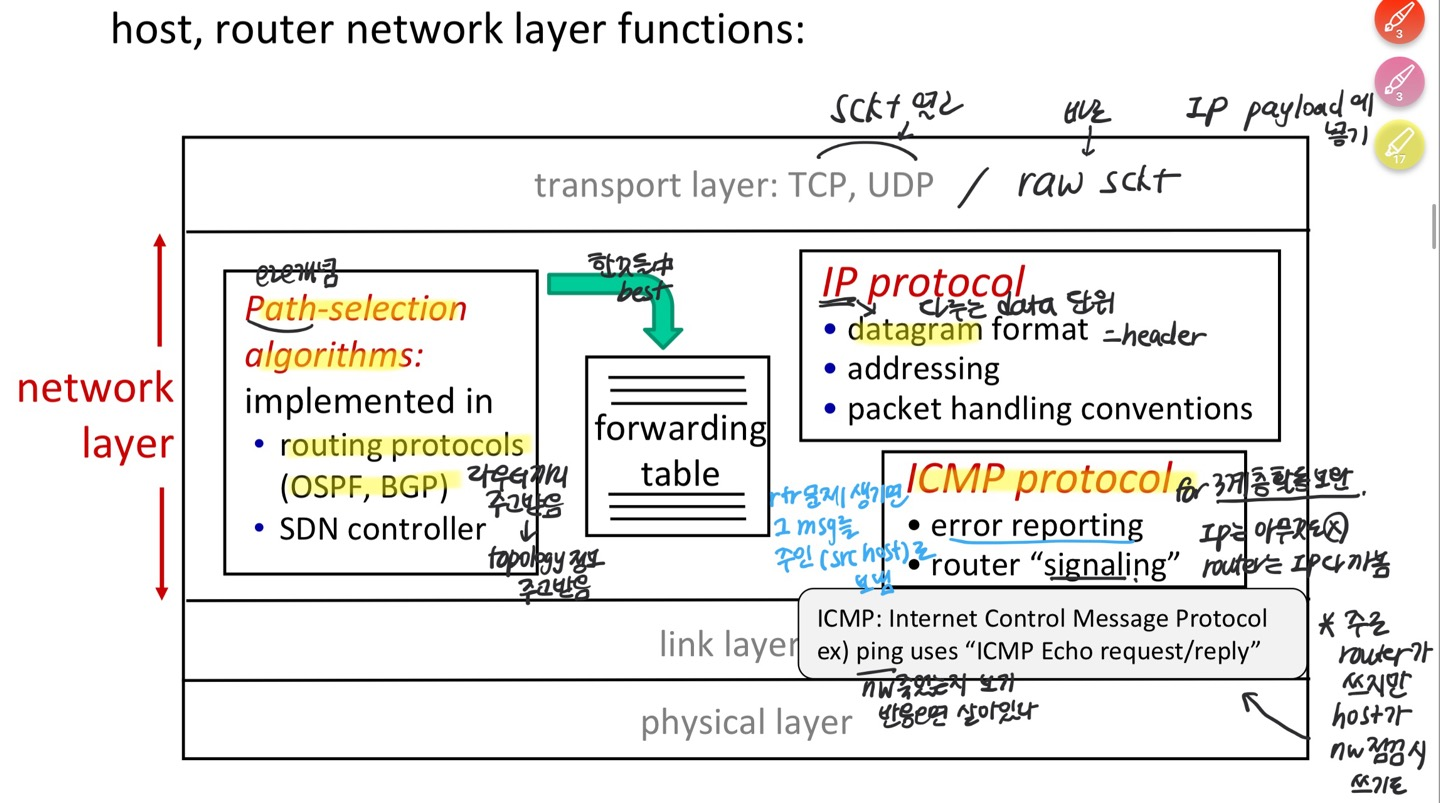
path-selection algorithms
routing protocols(OSPF, BGP) : 라우터끼리 전체 topology 정보를 주고 받음
그리고 나서 라우터 각자 path-selection algorithms (distributed 인터넷 철학)
forwarding table
path-selection algorithms 중 best of best
IP data packet, data plane할 때 쓰임
IP protocol
datagram : 다루는 data 단위
ICMP
for 3계층 보완. 어떻게 보완하냐?
error reporting : (IP는 아무것도 못함. router는 IP 다까봄.)
주로 router가 쓰지만, 엔지니어가 쓰는 급의 host가 nw 점검 시 ping을 날려봄.
IPv4 Datagram format
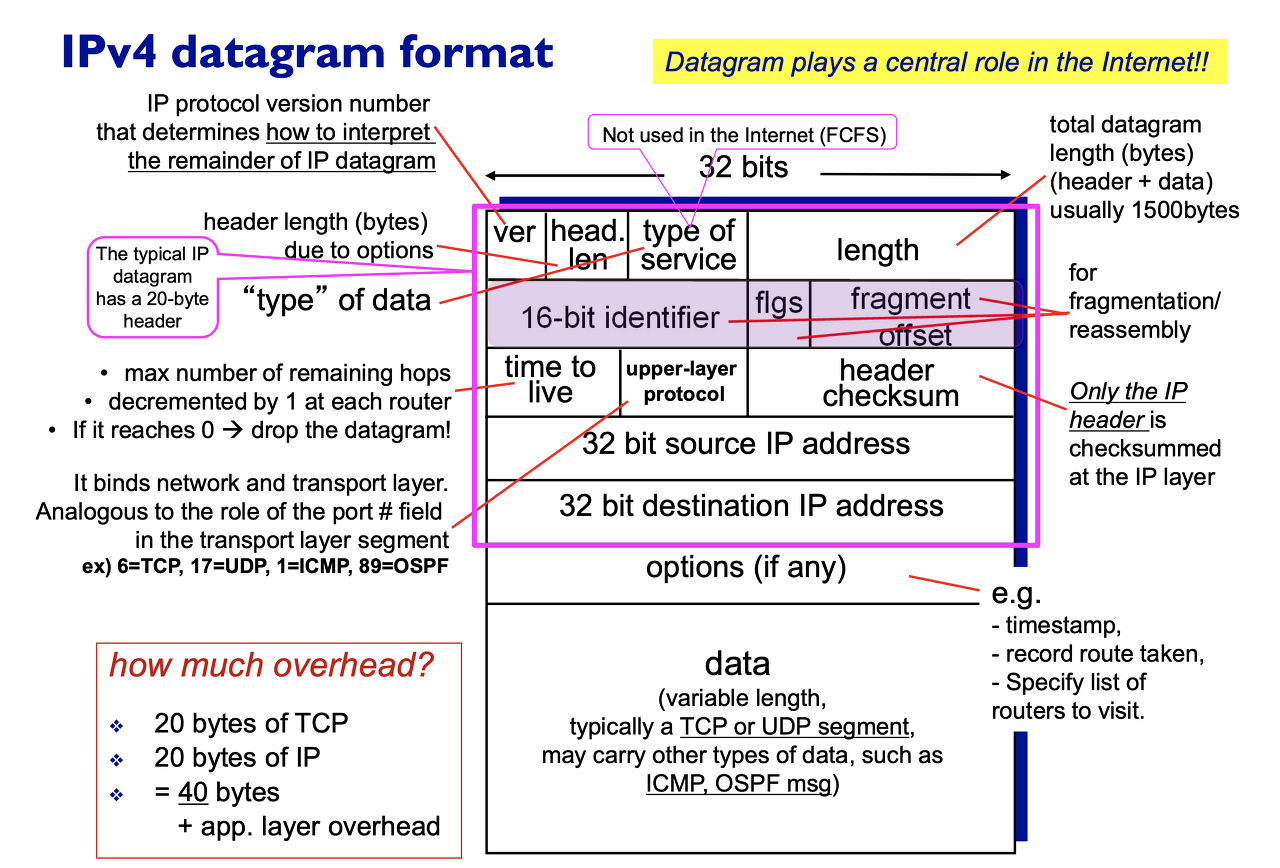
- version: 앞의 4 bit만 먼저 읽고 어떤 버전의 IP Datagram인지 확인.
- header length: IPv4 Datagram의 헤더 길이는 20bytes로 고정되어 있지 않다. (options 때문)
option의 timestamp, record route taken 등은 NW 엔지니어들이 개발할 때 테스팅 하는 옵션이기 때문에 user pkt에는 대체로 쓰지 않음.- 전형적인 IP Datagram의 헤더 length는 TCP와 같이 20 bytes.
- TCP, IP 프로토콜을 사용하는 메시지는 기본적으로 40 bytes의 오버헤드를 가짐. (IP 헤더와 20bytes + TCP 헤더 20bytes) (헤더도 버퍼를 차지. 적은 헤더로 메시지를 보내야 더 좋으니 오버헤드)
- type of service: 인터넷 IP protocol은 FCFS기 때문에 사용하지 않음.
- length: 전체 Datagram의 길이.
- Time to live: destination을 찾지 못 하고 돌아다니는 ghost traffic을 없애기 위한 time limit. TTL = 0이면 더이상 forwarding 하지 않고 drop.
- upper layer protocol: mux, demux에 사용. 1 protocol이 다수의 protocol을 support할 때 어떤 function의 sw를 call해야 하는지 판단, module에 전달. data의 내용이 TCP segment이면 TCP module에, ICMP이면 ICMP module에 전달.
→ IP Datagram의 body가 반드시 Layer 4의 segment X, 3계층 protocol일 수 있음- mux : 여러 입력 중 하나를 출력, demux : 하나의 입력을 여러 개의 출력으로 만들어줌 (decode)
- data: Layer 4 protocol이 읽는 내용이니 IP(Layer 3) protocol이 읽지 X.
- header checksum : only the IP header만 에러 첵섬
IPv4 fragmentation, reassembly
fragmentation 하는 이유: MTU(Maximum Transmission Unit = R)보다 크면 쪼개서 보내야 함. (들어오는 R보다 나가는 R'이 작으면 쪼개야 함)
Maximum Transmission Unit은 결국 R 값. link-level frame에 따라 R값이 달라짐.
라우터에 서로 다른 type의 link가 물려있을 수 있으므로 각기 다른 MTU값을 가짐.
큰 IP datagram이나 UDP Datagram at host는 IP계층에서 fragmentation 해줘야 함.
TCP는 MTU고려하여 MSS 결정. 따라서 TCP 들어간 IP pkt은 1st 단에서 fragmentation할 일 없음
다시 합치는 건? 중간 라우터 X. final destination "host" not router.
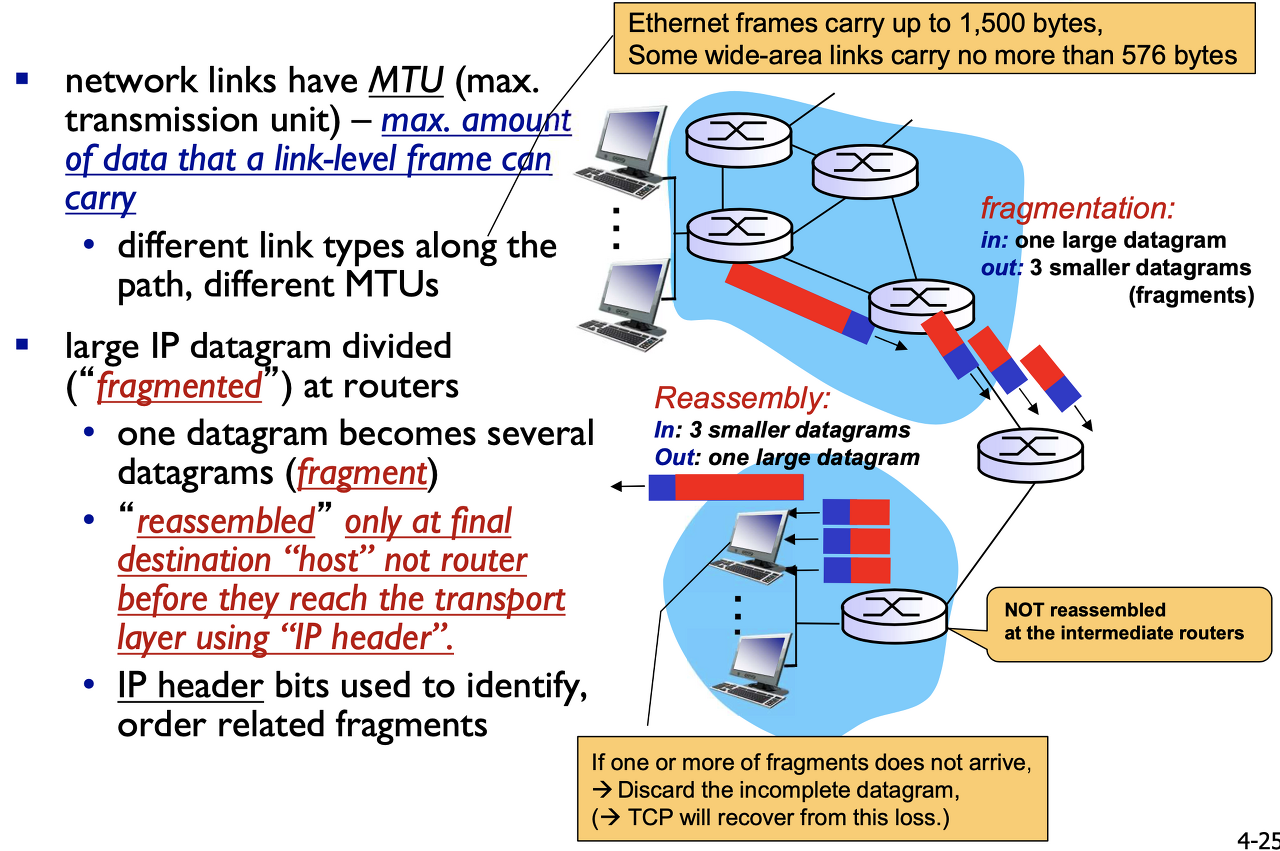

왜 IPv4 reassembly는 서로 다른 MTU size 때문에, host에서 내려온 UDP Datagram을 IP 계층에서 fragmentation한 패킷들을 다시 합치는 작업을 중간 라우터나 마지막 라우터가 아닌 destination host의 IP계층에서 해야할까?
- Packet switching은 packet by packet switching이라 각 sub packet들이 지나가는 경로가 다 다르기 때문에 individual하게 모든 라우터들을 지남. 이론상 하나의 라우터로 지나간다고 보장할 수 없기 때문에 중간 라우터에서 합칠 수 없음.
- 맨 마지막 라우터에서 합치면 되지 않을까? internet의 철학. stateless ! core network는 가능한 복잡한 일을 안 하고, simple하게 빨리 deliver하는 것이 목표. 복잡한 것은 host. 따라서 라우터 는 쪼개진건지 모름. independently 하게 pkt을 처리.
fragmentation 시에 헤더(20bytes)는 똑같이 복사되어 각 서브 패킷에 붙음
IPv4 fragmentation at router
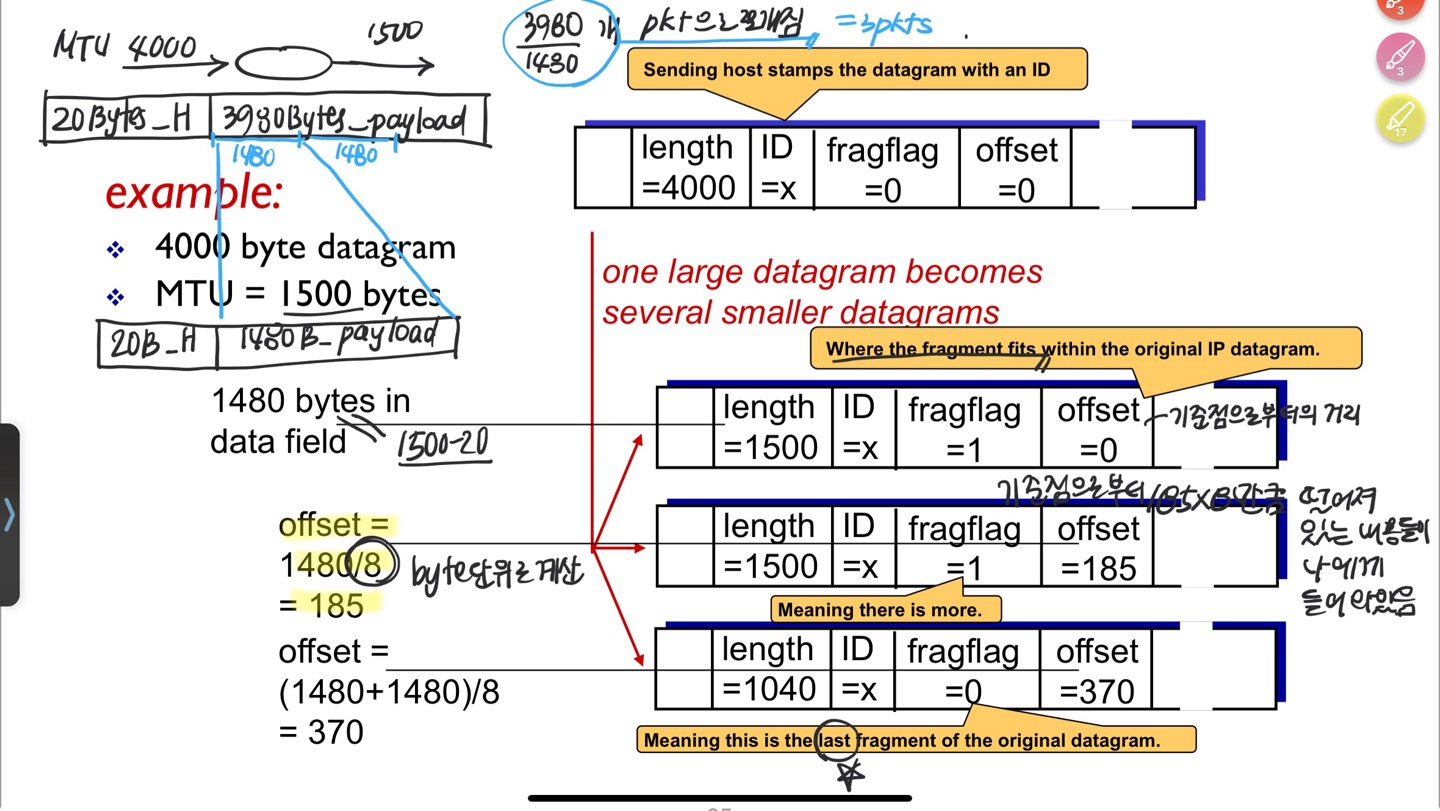
Quiz
- 4000 byte datagram ⇒ 20 byte header, 3980 byte body
- MTU = 1500 bytes ⇒ 20 byte header, 1480 byte body
20 byte 헤더는 다 넣고, 3980 byte짜리 body를 1480 byte로 쪼개어 넣는다.
결과적으로 세 패킷으로 쪼개지고, 세 패킷이 같은 패킷으로부터 쪼개졌다는 것을 알기 위해 동일한 ID를 줌. fragflag는 마지막 fragment일 때 0. offset은 몇 byte 떨어져있는 패킷인지. (8 bit 단위, octet으로 표기)
마지막 fragment의 length는 20 + ( 3980 - ( 1480*2 ) )
Keywords
- Switching rate is measured as N times line rate (line speed)
- Head-of-line (HOL) blocking can occur at an input(ingress) buffer(queue) due to a drawback of crossbar switching (Two pkts destined to the same output port cannot be switched at the same time)
- Why does the Internet not schedule packet depending on service level agreements (SLA) at output(egree) buffer? - Due to Network Neutrality
- What is Network Neutrality?
Net neutrality is the principle that Internet service providers and governments regulating most of the Internet must treat all data on the Internet the same, and not discriminate or charge differentially by user, content, website, platform, application, type of attached equipment, or method of communication. For instance, under these principles, internet service providers are unable to intentionally block, slow down or charge money for specific websites and online content.
- IPv4 datagram format
- What is a role of TTL?
- Why is ToS (Type of Service) field not used in the Internet?
- When is "upper-layer protocol" used?
- Does IP do checksum for PDU as well as header? yes
- IPv4 fragmentation/reassembly
- Can IPv4 fragmentation happen in the network layer only at a router? no
- Why is reassembly not performed at a router? (two reasons)
- Why is the average buffering in the e2e path related to RTT?
If RTT increases
-> packets' average waiting time in the output buffer of the path grows
in other words, more buffering happens as RTT increases.
'CS > Computer Network' 카테고리의 다른 글
| Network layer : Route aggregation & NAT (0) | 2023.12.09 |
|---|---|
| Network layer ; DHCP Protocol (0) | 2023.12.08 |
| Network Layer : The data Plane 총정리 (0) | 2023.12.06 |
| ch4 73~끝, ch5 1~7 (1) | 2023.12.05 |
| ch4 47~72 (2) | 2023.12.04 |


