
CS log
Decision Tree / Ensemble & Random Forest 본문
1. Decision Tree
1) 개념
데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반 분류 규칙 (if/else)를 만드는 것
최대한 균일한 데이터 세트를 구성할 수 있도록 분할하는 것이 필요!

이런 상태에서 어떻게 해야할까? 노란색 공의 경우 모두 동그라미로 구성, 빨강과 파랑 공의 경우는 동그라미, 세모, 네모가 골고루 섞여 있다. 따라서 가장 먼저 만들어져야 하는 규칙 조건은 if 색깔 == '노란색'
2) 장단점
장점 : 쉽다, 직관적이다, 피쳐의 스케일링이나 정규화 등 사전 가공 영향도가 크지 않다.
단점 : 과적합으로 알고리즘 성능이 떨어질 수 있기 때문에 트리의 크기를 사전에 제한하는 튜닝이 필요하다.
3) 결정트리의 파라미터
- min_samples_split : 노드를 분할하기 위한 최소한의 샘플 데이터 수 (default = 2), 작게 설정하면 분할되는 노드 수가 증가하여 과적합 가능성이 증가함. 과적합을 제어하는 데에 사용된다. 계속 분할하다가 데이터 수가 지정한 값에 도달하면 멈춘다.
- min_samples_leaf : 왼쪽과 오른쪽의 브랜치 노드에서 가져야 할 최소한의 샘플 데이터 수, 크게 설정하면 최소한의 샘플 데이터 수 조건을 만족시키기 어렵다. 비대칭적 데이터의 경우 작게 설정할 필요가 있다.
- max_features : 최적의 분할을 위해 고려할 최대 피처의 개수 (default = None)
- int형으로 지정하면 대상 Feature의 개수
- float형으로 지정하면 전체 피처 중 대상 피처의 비율
- sqrt (또는 auto): 전체 Feature 수의 제곱근 만큼 선정
- log: 전체 feature의 log2 만큼 선정
- max_depth : 트리의 최대 깊이 (default = none) : 깊이가 깊어지면 min_samples_split 설정대로 최대 분할하여 과적합할 수 있으므로 적절합 값으로 제어 필요.
- max_leaf_nodes : 말단 노드(leaf)의 최대 개수
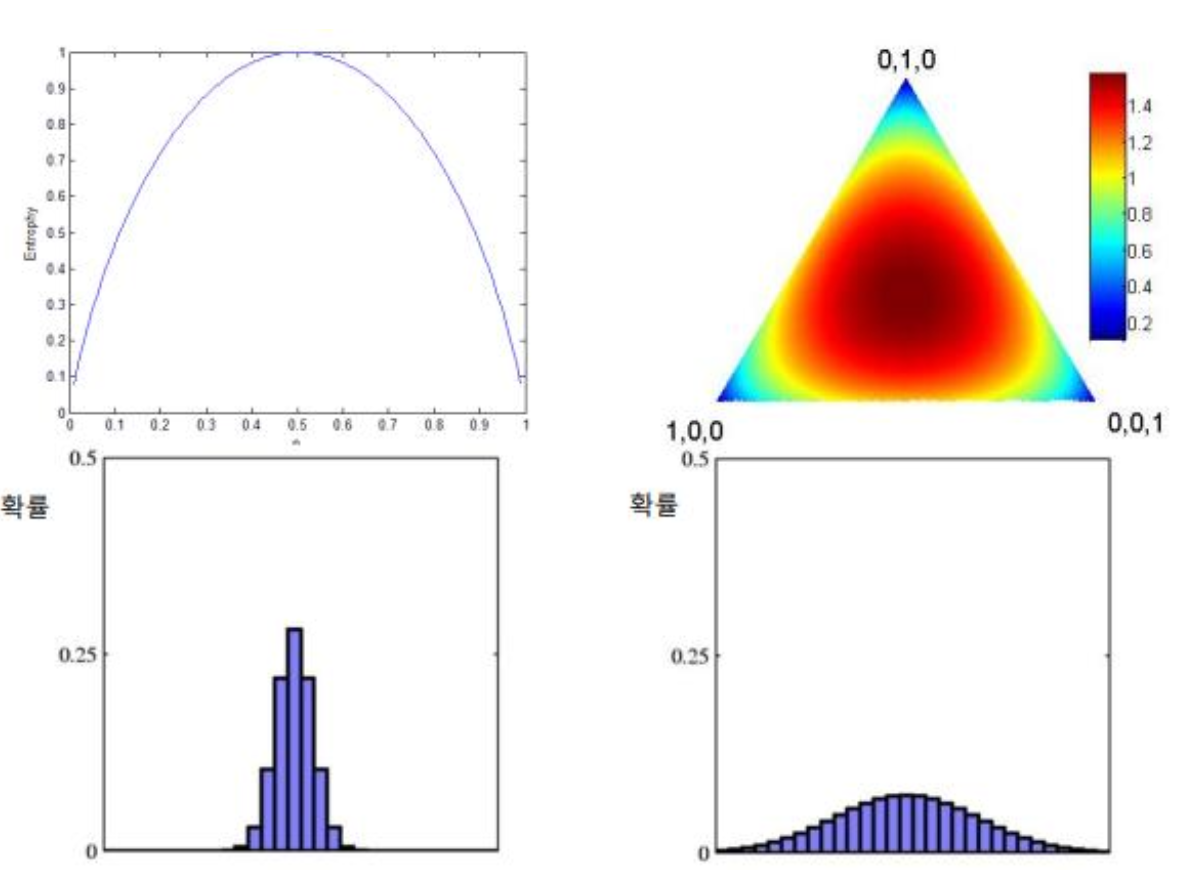
4) 정보의 균일도를 측정하는 방법
어떤 속성을 선택하는 것이 효율적인가? 분할한 결과가 가능하면 동질적인(pure)것으로 만드는 속성 선택
entropy
- 동질적인 정도 측정 가능 척도
- 원래 정보량 (amount of information) 측정 목적의 척도
- -p(c) : 부류 c에 속하는 것의 비율
CART 알고리즘

훈련 세트를 하나의 특성 k의 임계값 tk를 사용해 두 개의 서브셋으로 나눔
(크기에 따른 가중치가 적용된) 가장 순수한 (gini=0)에 가까운 subset으로 나눌 수 있는 (k,tk) 짝을 찾음
최대 깊이가 되면 중단 or 불순도를 줄이는 분할을 찾을 수 없을 때 중단
2. ensemble learning
ensemble : 여러 분류기(classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법
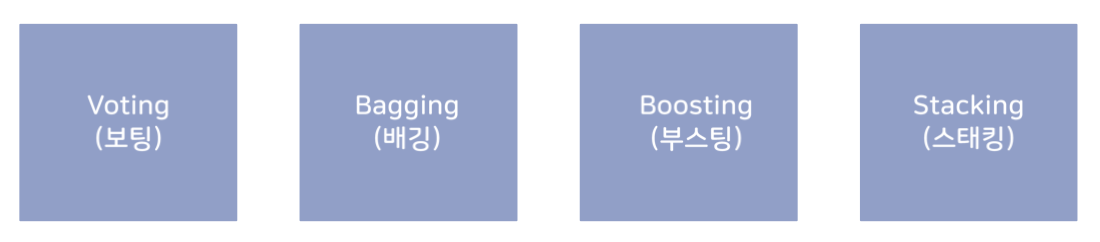
1) voting
서로 다른 알고리즘을 가진 분류기를 결합하는 것
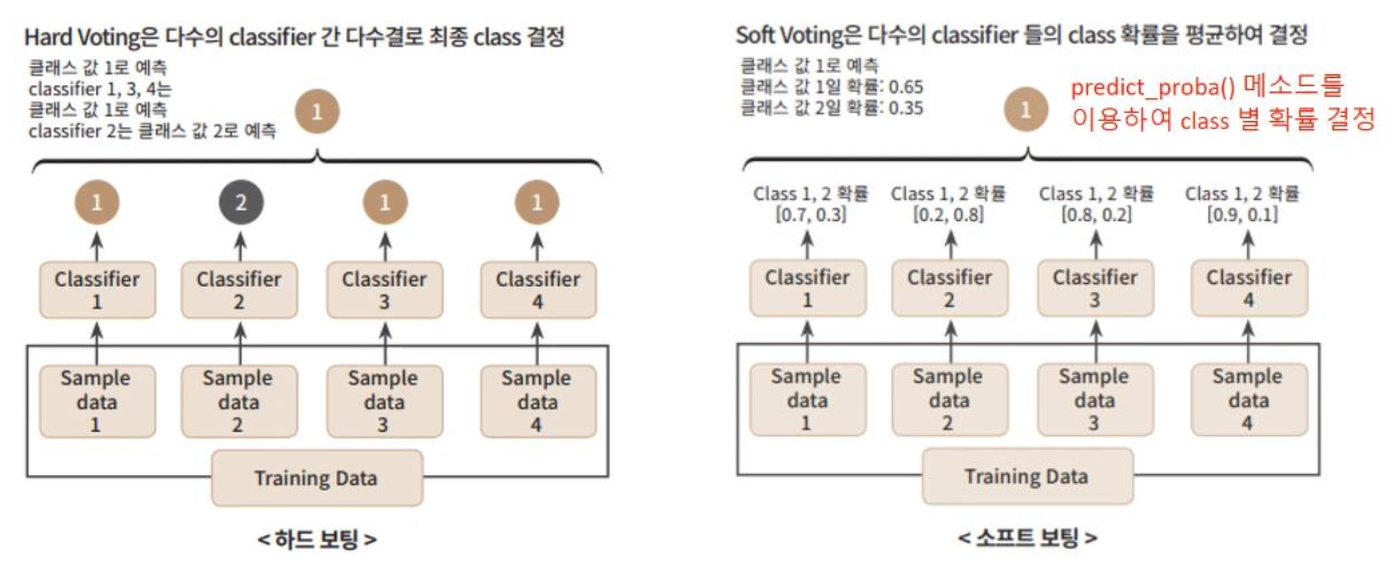
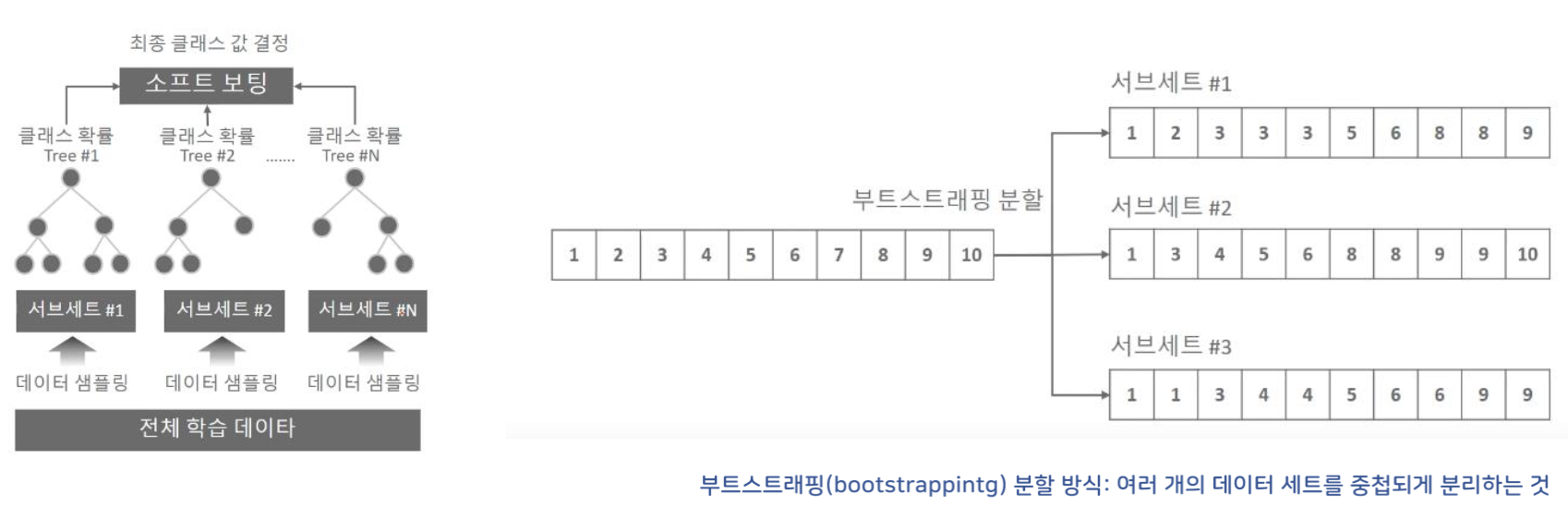
2) bagging
모두 같은 유형의 알고리즘 기반이지만, 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행하는 것
3) boosting
여러 개의 약한 학습기를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식
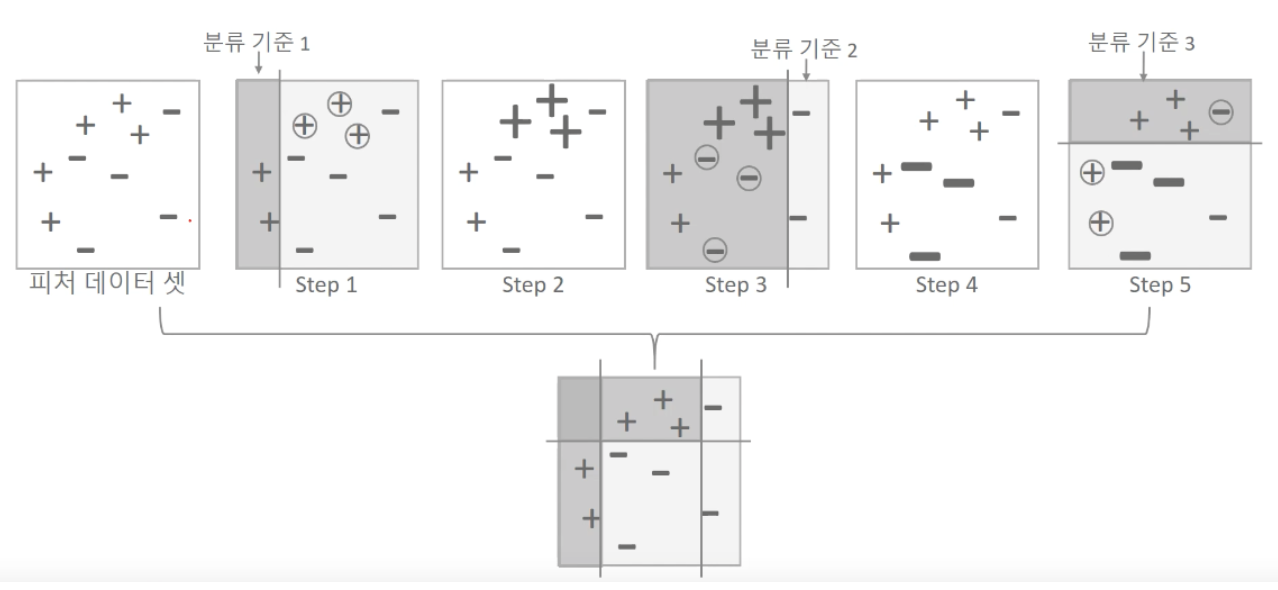
4) stacking
여러 다른 모델의 예측 결과값을 다시 학습 데이터로 만들어 다른 모델에 재학습시켜 결과 예측
3. random forest
- bagging의 대표적 모델
- forest : decision tree 여러 개를 base 모델로 사용
- random : 변수 무작위 선택 - 나무마다 독립변수가 다르게 들어가도록 변수의 수를 제한시킴
- 장점
- 앙상블 모델 중 비교적 빠른 수행 속도
- 높은 예측 성능
- dt 기반의 모델로 오버피팅 감소
- 단점 : 많은 하이퍼파라미터 및 튜닝에 많은 시간 소요
4. GBM
- boosting의 대표적 모델
- AdaBoost와 유사하나 가중치 업데이트를 경사하강법을 이용하여 과적합에도 강함
* 경사하강법 : 오류식을 최소화하는 방향성을 가지고 반복적으로 가중치 값을 업데이트하는 것
- 예측 성능은 GBM > 랜덤 포레스트
- 수행시간, 하이퍼 파라미터 튜닝 노력은 GBM > 랜덤 포레스트
5. XGBoost
- GBM에 기반하고 있지만 GBM의 단점인 느린 수행 시간 및 과적합 규제 부재 등의 문제를 해결
- 병렬 cpu 환경에서 병렬 학습이 가능해 기존 GBM 보다 빠르게 학습 완료
- 장점
- 뛰어난 예측 성능
- GBM 대비 빠른 수행 시간
- 과적합 규제
- 자체 내장된 교차 검증
- 결손값 자체 처리
'AI' 카테고리의 다른 글
| EfficientNet (0) | 2024.09.26 |
|---|---|
| ResNet (0) | 2024.09.26 |
| DL 기초 (ANN, DNN, CNN) (0) | 2024.08.13 |
| 회귀 regression (1) | 2024.07.24 |
| 분류와 회귀 (1) | 2024.07.24 |


