
CS log
GPT-1 본문
0. Abstract
unlabel된 text는 아주 많지만, labeled data for learning specific tasks is scarce
이런 unlabeled된 데이터를 버리지 않고
generative pre-training of a language model on a diverse corpus of unlabeled text 와 그와 더불어
discriminative fin-tuning on each specific task 를 사용해 성과를 냈다.
task-aware input transformations 의 pretraining -> fine-tuning 하는 과정에서 model architecture는 최소한으로 변경했다.
특히 general task-agnostic model에서 특정 task를 위한 모델보다 더 큰 성과를 보였다.
또한 12개의 tastk 중 9개의 task에서 state of the art를 냈다.
* agnostic이란?
https://velog.io/@cateto/ML-Model-Agnostic
[ML] Model Agnostic
출처(https://elapser.github.io/machine-learning/2019/03/08/Model-Agnostic-Interpretation.html한국어 자료가 있음에 지식 공유자님께 감사합니다. (\_ \_ )모델 경량화 논문에는 model
velog.io
1. Introduction
raw text로 부터 효과적으로 학습하는 것은 중요
왜냐하면 딥러닝 방식은 label된 데이터를 요구하는데, label 된 데이터는 부족하기 때문이다.
이에 model들이 unlabeled 데이터로부터 linguistic information을 뽑아내기도 하고, (but expensive)
심지어 supervision(labeled data로부터 학습하기)이 가능해도 unsupervised 방식도 성능을 높일 수 있다.
그러나 leveraging more than word-level info from unlabeled text의 문제점
1) text를 학습하는 데에, 즉 pretrained model 학습하는 데에 어떤 optimization이 가장 효과적일지 unclear
2) pretrained model을 fine-tuning하는데에 무엇이 가장 효과적인지 consensus가 없다.
현재는 task-specific에 맞게 model 구조를 바꾸고 복잡한 scheme을 추가 ➡️ semi-supervised learning 방법을 더 어렵게 만듦
따라서 본 논문의 목표 : semi-supervised approach for language understanding tasks using a combination of unsupervised pre-training and supervised fine-tuning, learn a universal representation (작은 adaptation으로도 다양한 task-specific 일 할 수 있도록)
step 1 : unlabeled data로 네트워크의 initial parameter(representation)을 배운다. (스스로 기본적인 특징이나 패턴을 알아냄)
step 2 : 이 파라미터들을 target task에 적용한다.
model architecture은
1. transformer 모델을 사용 ; structured memory for handling long-term dependencies(처음 나온 정보가 나중 정보에 오래 영향을 미침) in text
2. task-specific input adaptations derived from traversal-style 방법
2. Related work
semi-supervised learning
sequence labeling, text classification
가장 최근 연구 : more than word-level semantics from unlabeled data (ELMo)
word-embedding과 같이 word-level에만 머물지 않기 위해
Unsupervised pre-training
goal : to find a good initialization point (좋은 representation)
pre-training phase helps capture some linguistic information but LSTM과 같은 것들은 언어의 정보, 즉 긴 문장을 수용할 수 있는 능력이 안됨. 그러나 transformer, natural language inference, paraphrase detection, storpy completion 에서는 가능하다.
Auxiliary training objectives
unsupervised pre-training 의 목적함수를 supervised fine-tuning 할 때 auxiliary objective로 추가했다.
supervised learning 의 목적함수 + unsupervised learning 목적함수
3. Framework
steps for training
3.1. unsupervised pre-training
unsupervised corpus of tokens U={u1, ..., un} 이 있다고 하면 아래를 maximize하는 표준 언어 모델을 사용한다.

k = size of context window, 세타 = 신경 네트워크의 파라미터, stochastic gradient descent
네트워크에서 ui-k, ..., ui-1이 주어졌을 때의 ui의 확률값을 계산한다. 예를들어 I eat apple 이라는 문장에서 I, eat이 주어질 때 apple을 예측하는 확률값을 구한다.
transformer decoder를 사용함
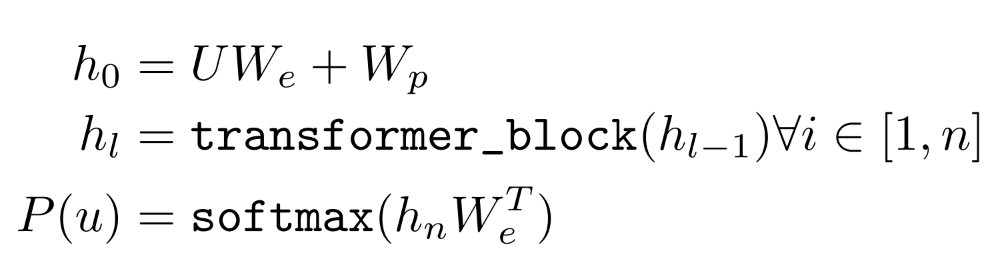
기존 decoder 부분에서 encoder layer가 없기 때문에 encoder-decoder attention을 제외하였고, 임베딩(We)후 potision embedding matrix( Wp )를 더하고, layer의 갯수만큼 decoder block을 통과하고 position-wise layer( W(T e) )를 거쳐 softmax로 확률값을 구한다.

좀 더 구체적으로는 ...
- input sequence를 받아 word embedding, positional embedding 수행 (이때 h_0가 위와 같이 표현됨)
- 그 다음부터 hidden state를 decoder 블락에 계속 놓어 학습시킴 (논문에서는 decoder block=12개)
- 마지막에 최종 hidden state 값을 활용하여 확률값 출력
왜 decoder를 사용했을까?
Pre-training 을 통해 'understanding'의 개념을 달성하고자 했다.
GPT 의 model 이 NLG(자연어 생성) 이나 NLM(자연어 모델링) 에 초점 맞춰져 있기 때문에 seq2seq 의 encoder-decoder 구조에서, 문맥벡터를 활용해 다른 시퀀스를 생성하는 decoder 구조만을 사용한 것이다.
(사실상 문맥벡터를 활용하는 encoder 값을 활용한 multi-head attention 부분도 없다.)
3.2. Supervised fine-tuning
after training model, we adapt the parameters to the supervised target task
fine-tuning은 supervised learning 이기 때문에 task에 따라 시퀀스에 따른 label 값을 부여해야함
C = labeled dataset, x1, ..., xn = sequence of input tokens, y = label
pretrained된 모델의 position-wise layer와 softmax layer 사이에 linear layer(Wy) 를 추가하여 각 task마다 label y 를 예측한다.
pretrain된 hidden state 값에 y를 예측하기 위한 가중치 W_y 가 곱해져 Linear layer로 들어가게 된다.
이제 데이터 셋에 label 값 y 가 존재하기 때문에, Likelihood function 은 y 값에 대한 확률을 사용한다.


L2 함수에 L1 함수를 더하여 보조적인 역할로 사용했을 때, 모델의 일반화와 학습 속도 향상에 도움이 되었다고 한다.
auxiliary objective은 아래 효과가 있음
1. improving generalization of the supervised model
2. accelerating convergence
가중치를 곱해주어 log likelihood를 최대화(최적화)

여기서 L1,L2,L3의 의미는?
Unsupervised pre-training 부분에서 사용한 function으로, 위에서는 input 으로 U (즉, unlabeled dataset) 이 들어가있지만, 이 새로운 L3를 정의할 때는 fine-tuning 에 쓰이는 C (즉, labeled dataset) 이 들어가 있는 것을 확인할 수 있다.
3.3 Task-specific input transformations
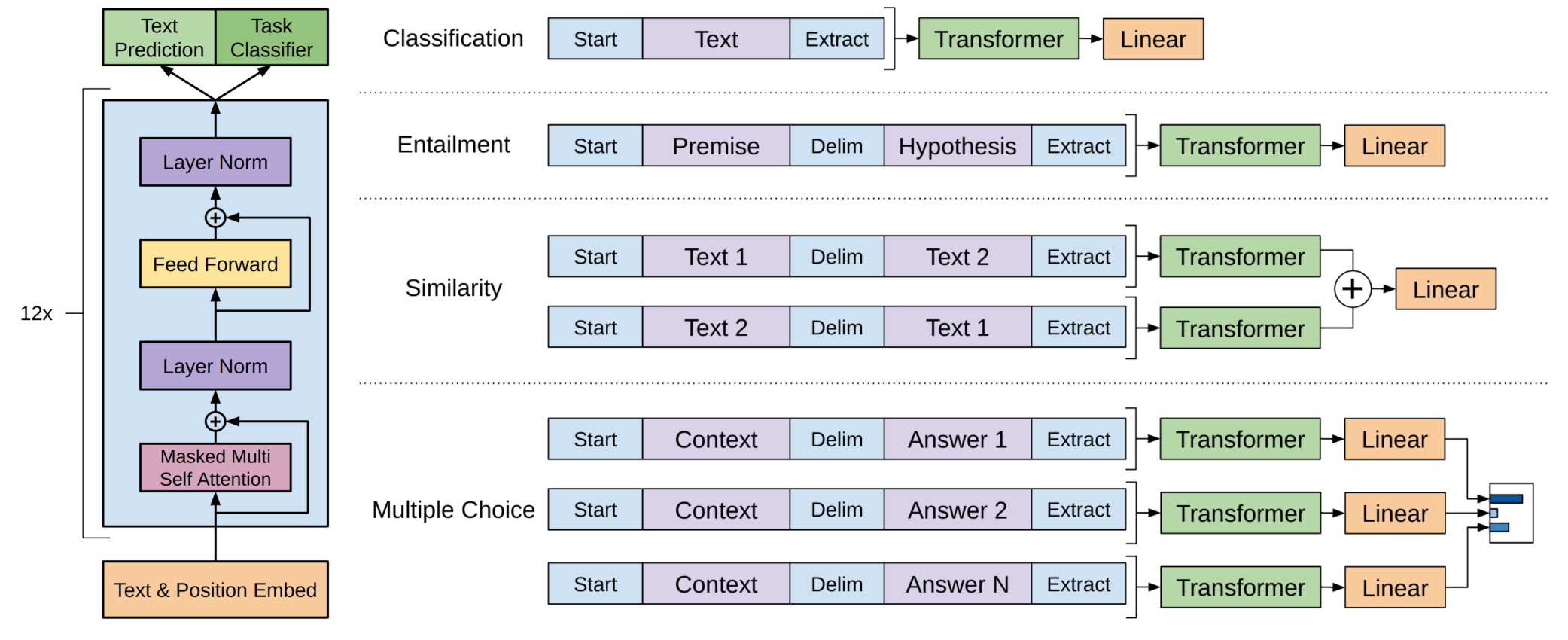
left : transformer 구조 and training objectives
right : input transformations for fine-tuning on different tasks. 모든 구조를 토큰 sequences로 바꿔서 pre-trained model(with linear+softmax layer)이 처리할 수 있도록 한다.
기존 연구 : learning task specific architectures on top of transferred(전송된) representations
상당한 양의 task-specific의 customization이 필요하여 전이 학습을 사용하지 않았다. (특정 작업에 맞게 모델을 많이 수정하거나 새로 설계해야 해서 오히려 전이 학습이 비효율적)
https://aws.amazon.com/ko/what-is/transfer-learning/
전이 학습이란? - 기계 학습에서의 전이 학습 설명 - AWS
전이 학습(TL)은 한 작업에 대해 사전 학습된 모델을 새로운 관련 작업에 맞게 미세 조정하는 기계 학습(ML) 기법입니다. 새로운 ML 모델을 학습하는 것은 대량의 데이터, 컴퓨팅 성능, 프로덕션 준
aws.amazon.com
전이 학습(transfer learning)이 특정 작업에 맞게 많이 수정해야 할 경우 효율적이지 않은 이유
- 전이 학습의 기본 개념: 전이 학습은 미리 학습된 모델의 지식을 다른 새로운 작업에 빠르게 적용하는 방식. 여기서 중요한 전제는 기존에 학습된 모델이 새로운 작업에 잘 맞아야 한다는 것. 예를 들어, 이미지 분류를 학습한 모델을 다른 이미지 분류 작업에 활용하는 거죠.
- 특정 작업에 맞춘 수정(customization)이 많은 경우: 만약 새로운 작업이 기존 모델과 크게 다르거나 복잡한 맞춤화가 필요하다면, 미리 학습된 모델이 그 작업에 적합하지 않다. 이럴 경우:
- 많은 수정을 해야 해서 결국 처음부터 모델을 새로 만드는 것과 비슷한 양의 작업이 필요해진다.
- 모델 구조(architecture) 자체를 많이 바꾸거나, 파라미터를 전부 다시 학습해야 할 수도 있다.
- 효율성 문제: 전이 학습의 장점은 기존 모델을 활용해 시간을 절약하고 데이터와 계산 자원을 아끼는 것인데, 수정이 많이 필요하면 그 장점이 사라진다. 새 작업에 맞게 너무 많은 변경을 하다 보면, 전이 학습을 쓰는 게 시간이나 자원 면에서 오히려 비효율적이 될 수 있는 것.
본 연구 : traversal-style approach (모델이 처리할 수 있도록 input의 순서를 바꾸는 것) 으로 전이학습을 최소한의 변화로 가능하게 함.
- classification : 기존 분류 문제와 같다. 단순히 linear 계층만 추가해주면 된다.
- textual entailment : 전제 p와 가정 h 를 사이에 $ 문자를 두고 concatenate (한 번에 네트워크에 forward)
- similarity : 두 문장의 순서가 존재하지 않는다. 따라서 문장 순서를 반영하기 위해
- input sequence를 수정((text1, text2), (text2, text1))하여 각각 모델에 forward하여
- 마지막 linear output layer에 넣기 전 element-wise로 합하여 출력한다.
- 문장 순서가 다를 때 모델이 어떻게 각각 반응하는지 살펴볼 수 있다.
- 같은 가중치로 결합한다.
- question answering and commonsense reasoning : document z, question q, a set of possible answers {ak}
- z;q;$;ak 형태로 concatenate
- 각 정답 리스트 k개 만큼의 각각 모델에 forward하여 리스트들의 softmax를 구해 가장 정답에 가까운 값을 구한다.
✨Contribution
- Unsupervised pre-training을 사용하여 대규모 텍스트 코퍼스를 학습에 사용할 수 있게 하였으며 덕분에 Supervised fine-tuning에서 많은 성능 향상을 얻어내었다.
- 입력을 교체하고 최소한의 레이어를 교체함으로써 각 task를 수행할 수 있다.
- sub object function인 Auxiliary training objectives 을 도입하여 labeled된 데이터 에서도 보다 원활한 학습을 진행하게 하였다.
4. Experriment
4.1 setup
unsupervised pre-training
BookCorpus dataset which allows the generative model to learn to condition on long-range information. (long term dependency 학습 가능한 긴 지문 데이터셋)
Model specifications
transformer decoder layer는 총 12층
self-attention head는 총 12개의 heads로 구성
position-wise feed-forward는 총 3072 차원이며 adam optimizer를 사용했다.
fine tuning은 λ를 0.5로 설정한 것을 제외하고는 나머지 하이퍼파라미터는 unsupervised와 거의 동일하다.
| pre-training | fine-tuning |
|
|
아래는 task 12개 중에 9개의 dataset에서 sota를 달성한 테이블이다. 소규모의 작은 데이터셋(STS-B 5.7k)그리고 다양한 크기(SNLI 550k)의 데이터셋에서 잘 작동함을 증명해내었다.



4.2 supervised fine-tuning
natural language inference : 문맥적인 함의를 읽어내는 것, 문장 간 관계를 알아내는 것 (전제, 반대, 중립)은 다양한 단어의 뜻, 상호 참조(누가 누구를 가리키는 알아내는 것), 단어와 구문의 모호함 때문에 어려움
➡️ 많은 문장과 언어적 모호함에도 불구하고 gpt-1은 sota 달성!
question answering and commonsense reasoning : single and nulti-sentence reasoning 이 필요함. 그래서 RACE dataset(중학교 고등학교 시험용 영어 문단과 퀴즈 자료) + story cloze test (여러 문단으로 이루어진 이야기의 문장 끝 마무리를 적는 test) 를 이용하여 sota 달성!
semantic similarity : 두 문장이 구문론적으로 일치하냐? 를 판단
개념이 rephrasing 되었는지 판단, 부정을 이해하는 것, 구문론적 모호함을 다루는것이 관건
classification : the corpus of linguistic acceptability 는 이 문장이 문법적으로 옳은지 아닌지를 판단한 것을 담고 있으며 이를 이용해 pre-trained 된 모델이 문법적으로 편향이 있는지를 테스트한다. 정확도가 아주 높게 나왔다 (sota)
5. Analysis
impact of number of layers transferred

왼쪽의 그래프는 layers수의 증가량에 따라 RACE와 MultiNLI에 대해 실험을 진행하였다. pre-trained 된 GPT의 레이어를 몇개를 가져올까 하는것인데 오른쪽으로 갈 수록 output에 가까운 레이어를 가져오게 된다.(수렴) 그래프를 보면 점점 성능이 올라가게 되는데 이는 각각의 레이어가 문제를 해결한다고 볼 수 있다. (layer의 개수가 증가함에 따라 정확도가 향상된다. layer # 12이후부터는 수렴 양상을 보인다.)
zero-shot behavior
* zero-shot performance : 모델이 한 번도 학습해본 적이 없는 새로운 작업이나 데이터를 접했을 때 그 작업을 성공적으로 수행하는 능력
왜 transformer의 language model을 pre-training 한 것이 효과적일까?
가설 1 : 기반이 되는 generative model이 우리가 평가하고자 하는 tasks를 실행하려고 배운다. 동시에 언어 모델의 학습 용량을 향상시킨다.
가설 2 : 더 구조화된 transformer의 attentional memory가 전이학습을 할 때 lstm에 비해 더 좋다.
지도학습을 한 fine-tuning이 없고, 생성 모델을 기반으로 하는 연속적인 휴리스틱 solution을 제안했다.
오른쪽 그래프는 GPT-1의 pre-train의 진행만으로 task마다의 다운스트림 테스크에 대한 성능을 보여주는 것 이다. 그래프를 보았을때 LSTM을 pre-train 시킨 것보다 GPT-1(transformer)이 높은 성능을 보여주고 있다. 여기서의 결과는 LM 자체가 파인튜닝,제로 샷 없이 문제를 해결하는 과정을 보여준다.

CoLA(linguistic acceptability), SST2는 classification을 의미
MRPC, STSB, QQP : semantic similarity
mnli, qnli : natural language reference test data
pretraining 과정이 없을 때 성능이 15% 하락
fine-tuning : 데이터 셋이 클 경우에 더 효과적 (1번째는 fine-tuning 한 것, 3번째 열은 안한 것)
끝에 갈 수록 데이터셋이 더 큼 (특히 4개)
- Sentiment analysis : 문장에 토큰을 append 시키고 출력을 , 로 제한하였다.
- winograd schema resolution : 명확한 대명사 2가지를 가능한 참조로 바꾸고 생성 모델이 치환 후 나머지 시퀀스에 대하여 더 높은 토큰의 로그 확률을 할당한다.
-
더보기문장에서 어떤 단어를 다른 단어로 바꿔본다.
바꾼 후의 문장이 더 자연스러워지면, 모델은 더 높은 확률로 그 문장을 맞는 문장이라고 판단한다.
-
- Linguistic Acceptability : 출력 토큰의 average token log-probability를 이용하여 thresholding으로 예측
-
더보기문장이 자연스럽다면 확률이 높고, 자연스럽지 않다면 확률이 낮을 것이다. 모델은 그 확률을 비교하여 "이 문장은 괜찮다" 또는 "이 문장은 어색하다"라고 판단한다.
-
- question answering : 문서와 질문을 입력으로 하여 생성되는 문장들 중에 가장 average log-probability가 높은 문장을 예측한다.
6. conclusion
task-agnostic
generative pre-training & discriminative fine-tuning
pre-training을 통해 process long-range dependencies which are then successfully transferred to solving discriminative tasks (question answering, semantic similarity assessment, entailment determination, and text classification, sota)
unsupervised pre-training에는 transformer과 datasets(text with long range dependencies)가 잘 어울림을 밝혀냄
reference
https://www.youtube.com/watch?v=4qv_ofZN5_U
'AI > NLP' 카테고리의 다른 글
| Speech-to-text API (0) | 2024.09.23 |
|---|---|
| Intro to ML: Language Processing (0) | 2024.09.23 |
| seq2seq learning with neural networks (0) | 2024.09.12 |
| GAN 논문 리뷰 (0) | 2024.08.30 |
| Attention is all you need - Transformer (0) | 2024.08.14 |


