
목록전체 글 (98)
CS log
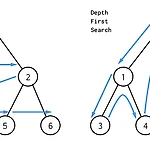 DFS & BFS
DFS & BFS
1. DFS/BFS 기초공통점그래프를 끝까지 탐색하기 위한 알고리즘이다 (완전탐색)to_visit, visited 리스트를 관리하는 것이 핵심이다!차이점탐색 순서 차이DFS는 상하로 우선 탐색, BFS는 좌우로 우선 탐색구현상의 차이점 : to_visit을 관리하고자 DFS는 스택, BFS는 큐(deque)를 사용codes overviewdef dfs(graph, start_node) : to_visit, visted = list(), list() # stack으로 관리 to_visit.append(start_node) while to_visit : node = to_visit.pop() if node not in visited : ..
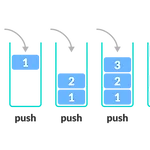 기초 자료구조
기초 자료구조
1. StackLIFO(후입선출, Last-in First-out)대표적인 stack 자료구조 활용 : ctrl + z 파이썬에서의 구현 ➡️ 리스트stack = []stack.append(1) # [1]stack.append(2) # [1,2]stack.append(3) # [1,2,3]stack.pop() # [1,2] stack 자료 구조의 단점 ? 1 빼려면 2,3을 모두 빼야 함. 시간복잡도가 매우 큼. 맨 안쪽에 있는 블럭을 빼려면 느림. 2. Deque, double-ended queue보통의 큐는 FIFO(선입선출, First-in First-out)뒤에서는 push만, 앞에서는 pop만 가능하다. deque는 앞/뒤 모두에서 push와 pop이 가능하다! python에서의 구현 ➡️ f..
https://cookie-chive-970.notion.site/Transformer-basic-paper-fd130fa0f7ad4e2fbb4572a98d798508?pvs=4 Transformer basic paper | Notionreferencecookie-chive-970.notion.site
 DL 기초 (ANN, DNN, CNN)
DL 기초 (ANN, DNN, CNN)
ANNAritificial Neural Network, 인공신경망사람 신경망 원리와 구조에 착안한 기계학습 알고리즘으로, 딥러닝의 기초가 됨 Perceptron인공신경망의 기본 요소이며, 신경 세포 하나를 의미함학습 방법 : 가중치 초기화 ➡️ 입력값과 가중치로 예측값 계산 ➡️ 예측값과 실제값 차이 계산 ➡️ 차이를 줄이도록 가중치 변경 ➡️ 반복 1) 단층 퍼셉트론 (single-layer perceptron)입력층과 출력층으로만 구성됨(은닉층x)한계 : XOR 게이트 구현 불가능 2) 다층 퍼셉트론(multi-layered perceptron MLP)은닉층 존재은닉층이 2개 이상인 신경망 -> 심층 신경망 (Deep Neural Network, DNN) * 같은 층의 노드 수를 늘리면 어떤 효과인..
📍문제https://www.acmicpc.net/problem/1182N개의 정수로 이루어진 수열이 있을 때, 크기가 양수인 부분수열 중에서 그 수열의 원소를 다 더한 값이 S가 되는 경우의 수를 구하는 프로그램을 작성하시오. 📍입력첫째 줄에 정수의 개수를 나타내는 N과 정수 S가 주어진다. (1 ≤ N ≤ 20, |S| ≤ 1,000,000) 둘째 줄에 N개의 정수가 빈 칸을 사이에 두고 주어진다. 주어지는 정수의 절댓값은 100,000을 넘지 않는다. 📍출력첫째 줄에 합이 S가 되는 부분수열의 개수를 출력한다. 📍풀이 방법combination 함수를 쓴다 -! 📍코드import sysfrom itertools import combinationsN, S = map(int,sys.stdin.re..